大量の画像の中から同一画像を探す方法
この記事はRecruit Engineers Advent Calendar 2018 の3日目の記事です。
こんばんは。 @kazu0716 です。ノリでアドベントカレンダーなんて参加しましたが、中々記事がかけずかなり焦りました・・・。クソ記事でも書かないよりマシということでご容赦ください。
今回は、大量の画像の中から、同一画像を見つける必要があり、色々調べたのでシェアしようと思います。
なぜやったか
仕事の中で 「不正ユーザは同一グループに属しており、利用する画像は使い回されている」 という仮説を調査する必要がありました。ただ、画像の数が膨大であり、人の目で見て処理をするのは非常に大変だったため、Scriptで処理できないかなと思ったのがキッカケです。
制約事項
仮説が正しかった場合、最終的にはシステム化することも検討していたので、どうせならそこまで見据えて技術を調査しようと思い、下記の制約の元でも実現できるものを探しました。
- 画像データが外部に流出してはいけない
- 数分内で大量の画像(数万件程度)の中から同一画像を検索できる
どのように実現したか
要素技術調査から、同一画像の調査精度、パフォーマンス調査まで実施しました。
要素技術調査
色々調査してく中で「Perceptual Hash」(以下、単純にhashと表現する)という手法を知りました。手法の詳しい内容に関しては下記に譲るとして、本技術の強みとしては、画像のhash同士を比較し、画像の類似度(実際はhash同士のハミング距離)を調べることができるという点にあると考えます。
tech.unifa-e.com kzkohashi.hatenablog.com
今回は、この手法を用いて大量画像の中から同一画像を検索できるPythonのライブラリである「image-match」の調査検証を行なっていきます。
どんなライブラリか
主に下記の2つの機能を持っています。
画像のhashを計算し、DB(ElasticSearch等)にデータを格納する(indexing)
- 入力: 画像のパス(ファイルパス/URLのどちらか)
- 出力: 特になし
DB内にあるデータを検索し、画像の類似度を表示する(search)
- 入力: 画像のパス(ファイルパス/URL)
- 出力: DB内部に格納されている画像との類似度、画像のパス(ファイルパス/URLのどちらか)
- 特定の類似度以上のもののみ出力することも可能
- 公式ドキュメントには0.40以下であれば同一画像と考えてよいとあり、今回はその値を閾値に設定
公式ドキュメントを参考に、簡単な使い方を紹介していこうと思います。今回python2系を使っているのは、image-matchの依存ライブラリであるscikit-image(0.12.x)がローカルの環境のpython3.7.0ではコンパイルでエラーになりpipでinstallできなかった(2018/11: 現在)ためです。
# pythonのVersion
$ python -V
Python 2.7.15
# 利用しているライブラリ
$ pip freeze
certifi==2018.10.15
chardet==3.0.4
dask==0.20.0
decorator==4.3.0
elasticsearch==6.3.1
idna==2.7
image-match==1.1.2
networkx==2.2
numpy==1.15.3
Pillow==5.3.0
requests==2.20.0
scikit-image==0.12.3
scipy==1.1.0
six==1.11.0
toolz==0.9.0
urllib3==1.24
$ ipython
In [1]: from elasticsearch import Elasticsearch
...: from image_match.elasticsearch_driver import SignatureES
In [2]: es = Elasticsearch()
# indexを指定しないとimagesというindexにデータが保存されます
# distance_cutoffで類似度が一定以上のものを結果から除外する
In [3]: ses = SignatureES(es, index="image_match_test",distance_cutoff=0.40)
In [4]: ses.add_image("./data/img/enm/65188/187284.jpg")
# 同一画像なのでdist=0.0になる
In [5]: ses.search_image("./data/img/enm/65188/187284.jpg")
Out[5]:
[{'dist': 0.0,
'id': u'-vh4b2cBZ9Tpnt1Kqfmo',
'metadata': None,
'path': u'./data/img/enm/65188/187284.jpg',
'score': 63.0}]
同一画像認識精度
次に、画像の類似度(実際は、ハッシュ同士のハミング距離)が0.40以下である場合同じ画像になるかを調べて見ました。 flaskで、画像search結果を表示する簡単なwebアプリを作り、人の目で見て同一でないものが混じってないかを調べて見ました。下記が、表示結果イメージになります。
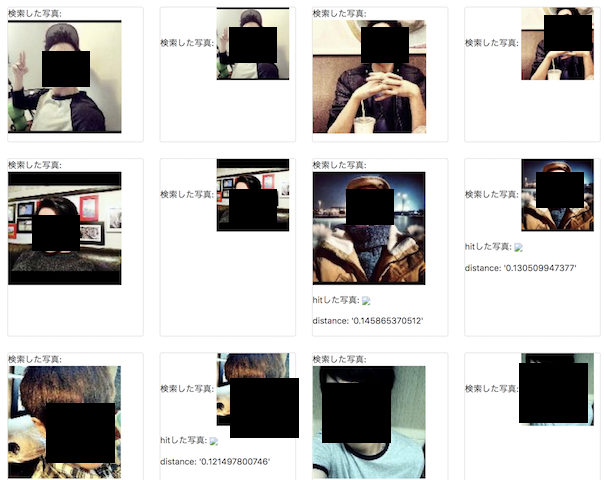
500サンプルくらいを見ましたが、違うものは混じってなさそうでした。ただ、0.40以上で判定され、同じだけど見逃してるものはあったかもしれませんが、今回は誤検知がないことを調べたかったので割愛しました。
パフォーマンスの調査
最後にパフォーマンスの調査を実施しました。利用したマシンのスペックは下記になります。
- OS
- MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)
- CPU
- メモリ
- 16 GB 2133 MHz LPDDR3
調査したのは、処理時間で主に下記の2点になります。
- indexingにかかる時間
| 対象データ数 | かかった時間(sec) |
|---|---|
| 21156 | 862.8 |
CPU負荷: 70%程度でした。時間がかかった理由としては、以下のようなコードで単純にforを回してデータを投入したからであると考えます。ただ、並列処理をしてもElasticSearchへのデータのindexingに限界があるため、そこまでパフォーマンスは上がらないと思われます。
# -*- coding: utf-8 -*-
from __future__ import print_function, unicode_literals, absolute_import
import time
import os
import glob
import threading
import imghdr
from elasticsearch import Elasticsearch
from image_match.elasticsearch_driver import SignatureES
es = Elasticsearch()
ses = SignatureES(es, distance_cutoff=0.40)
def add_images():
img_path = "./data/img/{}/*/*.jpg".format("koi")
image_list = glob.glob(img_path)
for img in image_list:
if imghdr.what(img) is not None:
ses.add_image(str(img))
else:
os.remove(str(img))
def main():
start = time.time()
add_images(service)
print ("elapsed_time:{0}".format(time.time() - start) + "[sec]")
if __name__ == '__main__':
main()
- searchにかかる時間(DB内部の画像データ数: 21156)
| 検索回数 | かかった時間(sec) |
|---|---|
| 10 | 1.38 |
| 100 | 9.72 |
| 1000 | 101.64 |
CPU負荷: 70%程度でした。2万程度の画像を対象に10回検索しても1秒程度で結果が返ってくるので、数分で検索は十分可能であると考えらます。また、検索時間は検索回数に比例しているように思わました。
まとめ
今回大量の画像の中から同一画像を見つけるためにimage-matchというライブラリの調査を実施しました。結果、最低限のコーディングでやりたきことが実現でき、かつローカルでもそれなりにパフォーマンスを発揮することがわかりました。今後は、まずは仮説の立証を行い画像の使い回しを確認し、その後システム化検討の際には、image-matchを検討の1候補にしようと思いました。
最後に
時間を決めて取り組みましたが、あまり内容のある記事を書けなかったので、短時間で人並みの記事が書けるように数を積み重ねることと、outputをイメージしてinputすることで、効率的に成長できると感じたため、inputばかりでなく、こういったブログ等でのoutputの機会を増やしていこうと思いました。