AtCoder Biginner 192 「D - Base n」を解いてみた
目的
問題
- 文字列(X)と、整数(M)が与えられ、文字列Xをn進法で数値変換した際に、M以下になるような種類を数え上げる
- Xは数値の文字列であり、その中で最も大きい整数d(0~9)とし、n >= d + 1以上の範囲を探索する
- 例
- X=22に含まれる最も大きい数字は2であり、10以下の種類は2種類になる
- 22を3進法表記とみなして得られる値は8
- 22を4進法表記とみなして得られる値は10
- 22を5進法表記とみなして得られる値は12
# input 22 10 # output 2
アプローチ
問題をどのように解いていくかの見立てを立てていく
計算量の見立て
dを1つづ増やしていく(線形探索)と、非常に時間かかりそう(実際TLEになった)
- M =< 1018 であり非常に大きい数であるため、O(n)だと終わらない
二分探索(binary search)で探索する
- nを増加させた際に、文字列Xをn進法で数値変換した値は単調増加する(例参照)ため、二分探索法が利用できる
- O(log n)で探索が終わるので、制限時間内に終わる
- 今回は、問題条件の実装、二分探索の利用までは気付けたが、時間不足と、二分探索の理解不足でACまで至らず・・・orz
- 線形探索し、TLEした
必要な機能
- 入力値の取得
- Xのうちの最大値 d を求める機能
- 10進数をn進数に変換する機能
- 数値の範囲を探索する機能
- 二分探索法で探索する
実装
実装する上で詰まった部分を説明していく
from collections import deque def base10_from(num, base): i, s, que = 0, 0, deque(list(str(num))) while que: s += int(que.pop()) * base ** i i += 1 return s def binary_search(x, m, d): if len(x) == 1: if int(x) > m: return 0 else: return 1 low = d high = m + 1 while high - low > 1: mid = (low + high) // 2 guess = base10_from(x, mid) if guess > m: high = mid else: low = mid return low - d def main(): X, M = input(), int(input()) d = max(list(map(int, list(X)))) print(binary_search(X, M, d)) if __name__ == '__main__': main()
最大値 d を求める機能
- dの取得は、文字列Xをlist化し、それぞれの要素をintに変換した上で、組み込み関数であるmax()を使って、list内の最大値を取得している
def main(): X, M = input(), int(input()) d = max(list(map(int, list(X)))) if __name__ == '__main__': main()
10進数をn進数に変換する機能
- 数値num, 基数baseを受け取り、それらを下記の考え方の基づき計算する
- ちなみに、各桁の数値の取得は、文字列をlist化、stackに変換し、桁の小さい方から取得している
- listのままでも実装可能であるが、pythonでlist型のpopは線形探索(O(n))で低速
collections.dequeを利用した際には、popはO(1)になる
def base10_from(num, base): i, s, que = 0, 0, deque(list(str(num))) while que: # NOTE: i桁目の数値を計算する s += int(que.pop()) * base ** i i += 1 return s
数値の範囲を探索する機能
Xが1桁の場合のみ、特殊な場合になるため注意が必要
- Xが1桁の場合の場合dの値に寄らず、解が決まる
X > Mの場合は、解なしX <= Mの場合は、dの値を変化させても値が変わらないため、1種類のみになる
- Xが2桁以上の場合に、二分探索を実施
- highは、解が必ずそれ以下になる十分大きな値であれば良い
high - low > 1の間は、整数midが存在するため、その間は計算を続ける
def binary_search(x, m, d): if len(x) == 1: if int(x) > m: return 0 else: return 1 low = d high = m + 1 while high - low > 1: mid = (low + high) // 2 guess = base10_from(x, mid) if guess > m: high = mid else: low = mid return low - d
学び
- 二分探索早いし、よく使うのでこれを機会に理解できて良かった
「JOI 2008 予選 5 - おせんべい」を解いてみた
目的
- Atcoderで上を目指すべく、「競プロ初中級者100問」を解いている中でpythonの仕様で面白い問題に直面したので共有する
- 言語はpython3系(pypy7.3 or python3.8.5)を利用している
問題
- 要約: おせんべいの表を0, 裏を1とした際に、与えられた行列R(最大10) × C(最大10000)の行列の表の数を最大化する
- JOI = 日本情報オリンピック
ポイント
計算量に関して
単純な全探索でなく、問題の条件/性質より探索範囲を絞り込む必要がある
全ての数を探索した場合 2R * 2Cとなり、全部の組み合わせを求めることは不可能(O(2R+C))
- ちなみに、「2100000 ≒ 9.99 * 1030102」通りという回数を全探索することになる
そのため、Rに関して全探索したのちに、その場合に関して、Cの探索を行う(O(2RRC))
- ちなみに、「2 ^ 10 * 10 * 10000 = 1.024 * 108」となり、何とか完了することができる
公式の解説通りに解いたと思われる
実装
- 行に関してbit全探索を行い、その上で各列に関して数え上げ、ひっくり返すかどうか考える
- 各列に関して数え上げ、その列における値において1が多ければひっくり返す、そうでなければそのままとする
R, C = map(int, input().split()) S = [list(map(int, input().split())) for _ in range(R)] ans = 0 range_r, range_c = range(R), range(C) S_ini = [[0] * C for _ in range_r] for i in range(2 ** R): bit = bin(i)[2:].rjust(R, "0") s = 0 S_copy = S_ini for j, b in enumerate(list(bit)): if b == "1": sj = S[j] S_copy[j] = list(map(lambda x: (x+1) % 2, sj)) else: S_copy[j] = S[j] for c in range_c: cnt = 0 for r in range_r: if S_copy[r][c] == 1: cnt += 1 s += max(cnt, R-cnt) ans = max(ans, s) print(ans)
- ちなみに、pypyでなくpython3で実行した場合はTLEになる(11s以上でTLEに・・・)
実行結果
- 何とかACすることができた(2秒以上かかっているので非常に遅い・・・orz)
気になったポイント
最初に、標準ライブラリのdeepcopyを利用し解いたが、非常に時間がかかった
from copy import deepcopy R, C = map(int, input().split()) S = [list(map(int, input().split())) for _ in range(R)] ans = 0 range_r, range_c = range(R), range(C) for i in range(2 ** R): bit = bin(i)[2:].rjust(R, "0") s = 0 S_copy = deepcopy(S) for j, b in enumerate(list(bit)): if b == "1": sj = S_copy[j] S_copy[j] = list(map(lambda x: (x+1) % 2, sj)) for c in range_c: cnt = 0 for r in range_r: if S_copy[r][c] == 1: cnt += 1 s += max(cnt, R-cnt) ans = max(ans, s) print(ans)
- おせんべいのinputを保持するSをdeepcopyを利用して計算した場合、非常に時間かかる(10s近くかかるが、宣言時間がザルのためACできるww)
- deepcopyはpython仕様上遅いようである
- ちなみに、pypyでなくpython3で実行した際にはさらに遅くなる・・・・deepcopy不使用の際に10s以下だったdata4でTLEになる
まとめ
- deepcopyは極力使わない方が良さそう
引き続き修行を続けよう
「JOI2007本戦C 最古の遺跡」を解いてみた
目的
- Atcoderで上を目指すべく、「競プロ初中級者100問」を解いている中で面白い問題に当たったので共有する
- 言語はpython3系(pypy7.3 or python3.8.5)を利用している
問題
- 要約: 複数(最大3000個)の点(x,y)が与えられ、それら4つで正方形が作れるか、いくつか作れる場合はその面積の最大値を求める
- JOI = 日本情報オリンピック
ポイント
計算量に関して
単純な全探索でなく、問題の条件/性質より探索範囲を絞り込む必要がある
点は最大3000個与えられるため、組み合わせ(nC4)で全部の点の組み合わせを求めることは不可能(計算量的にはO(n4))
- n=3000の場合「3,368,254,124,250 通り」あるため、制限時間内に実行完了することは出来ない
そのため、正方形である性質を利用し、4つの点ではなく、2点のみ求め、残りの2点が存在するかを求める
- この場合は、計算量はO(n2)となり制限時間内に実行可能になる
- n=3000の場合「4,498,500通り」
- 点が存在する場合の探索は、さほどコストにならない
- この場合は、計算量はO(n2)となり制限時間内に実行可能になる
正方形の性質
- 計算量に関しては、下記等でも解説されてはいるが、正方形の性質に関して少し深く考える
kakedashi-engineer.appspot.com
- 図1. のように、点p1, p2を決定した場合、p3, p4の座標はそれぞれ下記のようにp1, p2のx, y座標の情報を用いて求めることができる
- 入力座標にsortをかけた場合には、下記の2パターン(p2のy座標がp1のy座標よりも大きい or 小さい)があるが、全ての2点に関して探索するため、どちらか好きな方で考えれば良い

- ちなみに、pythonの2次元配列をsortすると下記のようになる
N = int(input()) P = [] for _ in range(N): x, y = map(int, input().split()) P.append((x, y)) # ここでsortする P.sort() print(P) # sortなし [[9, 4], [4, 3], [1, 1], [4, 2], [2, 4], [5, 8], [4, 0], [5, 3], [0, 5], [5, 2]] # sortあり [[0, 5], [1, 1], [2, 4], [4, 0], [4, 2], [4, 3], [5, 2], [5, 3], [5, 8], [9, 4]]
listの計算量に関して
- 最初は何も考えずに、listを利用し
list_a in list_Aで判定していたが、配列検索O(N)になってしまうのでTLEに・・・
from itertools import combinations N = int(input()) P = [list(map(int, input().split())) for _ in range(N)] P.sort() C = combinations(P, 2) ans = 0 for p1, p2 in C: x1, y1 = p1 x2, y2 = p2 p3 = x1 + y1 - y2, y1 + x2 - x1 p4 = x2 + y1 - y2, y2 + x2 - x1 if list(p3) in P and list(p4) in P: ans = max((x2 - x1) ** 2 + (y2 - y1) ** 2, ans) print(ans)
- set型かdict型でO(1)で検索する必要がある
- 結構この辺の仕様が、意識から抜けてた・・・非常に恥ずかしいミス
- set型を利用しAC(解けた)
from itertools import combinations N = int(input()) P = [] for _ in range(N): x, y = map(int, input().split()) P.append((x, y)) P.sort() C = combinations(P, 2) ans = 0 st_P = set(P) for p1, p2 in C: x1, y1 = p1 x2, y2 = p2 p3 = x1 + y1 - y2, y1 + x2 - x1 p4 = x2 + y1 - y2, y2 + x2 - x1 if p3 in st_P and p4 in st_P: ans = max((x2 - x1) ** 2 + (y2 - y1) ** 2, ans) print(ans)
- ちなみに、
x in setは早いが、それ以上にlistをsetに変換することが、x in listより低速であるため、注意が必要- set変換を毎回行うとかだと、非常に低速になる
- 1,2回とかしか使わないなら、setへの変換コストが大きいのでlistのまま利用した方が良い
pypyの利用メモリに関して
メモリ制限に引っ掛かりpypyでは通らない・・・64MBと通常のAtcoderの条件よりも厳しいため(Atcoderでは256MB)
基本的にpypyの方が高速であるが、メモリを多く喰うことがAtcoderを解いていて見受けられる
- python3の方が速い場合もある、順列の計算で標準ライブラリを使った場合もわずかにpython3の方が早かったりした
学び
- dict/setの検索は爆速、listはクソ遅いという仕様の再認識
- pypyメモリ喰いがち(下記の情報もあり場合よりけり? ただ、Atcoderで書く50行以下のscriptでは喰いがち)
- まだまだ、勉強が足らない・・・
serverless frameworkを使って、cloud functionを立ち上げてみた
何をするの?
serverless frameworkを使って、Cloud Functionを立ち上げてみました。
なぜやるの?
副業でcloudfunctionを使って、APIを構築することになったためです。
手動でscriptを構築するよりも、今後のことを考えると良いことがたくさんあるのと、AWS lambdaでは、利用したことがあったのですが、Cloud Functionではなかったので、良い機会だと思いTryしてみました。
何をしたの?
serverless frameworkを使って、cloud functionを立ち上げるまでにやったことを記載します。
導入で知っておくと良さそうなこと
「マジ初めてserverless frameworkとか聞きました!」って人向けに、さっと事前知っておいた方がいいことをまとめてみました。
そもそも「serverless framework」って?
Serverless Framework はServerless Applicationを構成管理デプロイするためのツールです。詳細は下記の記事を見ていただくのが良いかと思いますが
メリットとしては、上記の記事でも語られていますが
- コマンド1行で、さくっとDeployできる (もちろん、AWSやGCPとの認証するような設定はしないといけないですが)
- 構成管理が抜けがちな、FaaS(Function as a Service/ lambdaやCloud Functionのようなもの)の構成管理(≒ IaC化)が手軽にできる
- ローカルでテストでき、効率的に開発できる(自前でeventデータを作成し、任意のinputを用いて実行できます)
の3点かなと思っています。ローカルテストに関しては、こちらの記事でコマンドを確認すると良いかと思います。
以前、zappa というツールを使ってみたことがあったのですが、aws lambda/ pythonでしか利用できないのに対し、serverless frameworkは様々なサービス(AWS/GCP)や言語(javascript/python/golang等)に対応している分、汎用性が高いツールです。メンテナンスも頻繁であるため、基本的にはこちらを使うのが良いかと思います。
やったこと
- この辺の記事を参考にしました
install方法
serverless frameworkのインストール
公式docを見るといくつか方法がありますが、今回は npm を使って、Macにインストールしました。理由は、Reactを書いたり、typescriptを使うのでnode jsがインストールされているためです。npm = Node Package Manager でnode jsのインストールが必要になります。node jsのインストールですが、僕はnodebrewを使ってイントールしました。 node js ってなんぞや?って人は ここをみてください。
# グローバルインストール
$ npm install -g serverless
# serverlessの情報(エラーになってますが、`Your Environment Information ` をみていただければ、私の実行環境がわかるかと思います。 )
$ serverless info
Serverless Error ---------------------------------------
This command can only be run in a Serverless service directory. Make sure to reference a valid config file in the current working directory if you're using a custom config file
Get Support --------------------------------------------
Docs: docs.serverless.com
Bugs: github.com/serverless/serverless/issues
Issues: forum.serverless.com
Your Environment Information ---------------------------
Operating System: darwin
Node Version: 14.9.0
Framework Version: 1.82.0
Plugin Version: 3.8.3
SDK Version: 2.3.1
Components Version: 2.34.9
templateの作成
sls(serverless)コマンドを実行し、templateを作ります。実行すると、下記のようなファイルが作成されます。
# serverless frameworkを使うのに必要なモジュールのインストール $ npm install --save serverless-google-cloudfunctions # company-hpのディレクトリの下にpythonのtemplateを作成する $ sls create --template google-python --path company-hp # ディレクトリ構造 $ tree company-hp company-hp ├── main.py ├── package.json └── serverless.yml
cloud functionの設定
GCP認証突破のために、事前にサービスアカウントを作成し、そのCredential情報を用います。下記を参考にしながら作成しました。
設定ファイルである serverless.yml を編集し、適切な設定に変更します。
$ cat serverless.yml| head -n 15 service: company-hp provider: name: google stage: dev runtime: python37 region: asia-northeast1 # regionを東京に指定する project: xxxxxxx # 自身の利用するProject名に変更する # The GCF credentials can be a little tricky to set up. Luckily we've documented this for you here: # https://serverless.com/framework/docs/providers/google/guide/credentials/ # # the path to the credentials file needs to be absolute credentials: ~/.gcloud/test.json # サービスアカウントのアカウントkey(json file形式)への絶対パスを記載する frameworkVersion: '1'
deploy
早速deployをしようとしたのですが、エラーになってしまいました。
$ sls deploy ==省略== Error -------------------------------------------------- Error: Cloud Deployment Manager V2 API has not been used in project xxxxxxx before or it is disabled. Enable it by visiting https://console.developers.google.com/apis/api/deploymentmanager.googleapis.com/overview?project=xxxxxxx then retry. If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry.
どうやら、APIの有効化の手順が抜けていたようなので実行します。
$ gcloud services enable deploymentmanager.googleapis.com cloudfunctions.googleapis.com storage-component.googleapis.com logging.googleapis.com
gcloudコマンドインストール、および初期設定できていない方は、こちらを参考に実施すると良いと思います。
APIを設定すると、無事deployできました。
$ sls deploy ==省略== Serverless: Done... Service Information service: company-hp project: xxxxx stage: dev region: asia-northeast1 Deployed functions first https://asia-northeast1-xxxxx.cloudfunctions.net/company-hp-dev-first ******************************************************************************************************************** Serverless: Announcing Metrics, CI/CD, Secrets and more built into Serverless Framework. Run "serverless login" to activate for free.. ******************************************************************************************************************** ......
まとめ
さくっと、GCPでもserverless frameworkでCloud Function Deployできました。結構、lambdaとかCloud Functionは作って放置されがちなんですが、お手軽に構成管理もテストもできるので是非使ってみてはいかがでしょうか?
また、以前 AWS AppSyncを使って、GraphQLのバックエンドをserverless frameworkを使って作りました。よりスピーディな現場では、このような小さく初めてスケールする仕組みを使っており、アプリケーションエンジニアのみでほぼ全てが完結する世界も広がってるなーと思いました(Gloud ServiceのIAMの適切な設定等では、クラウドエンジニアは必要ですが)。今度時間があれば、その時の話でも書こうと思います。
はじめてのreact-nativeでHelloWolrd
何を書くの?
react-nativeのアプリ、特にiOSのHello-World的なことをします。
なぜ書くの?
副業でお世話になってる、ヘルスケアのベンチャー企業で、 急遽iOSのアプリを書くことになったのですが、 アプリ系は全くなので0から勉強しようと思って、やったことを書こうと思います。
何をしたの ?
やったことは、下記になります。
環境準備
この辺を参考にして、構築しました。 といっても、x-code、homebrew、node、react-nativeといったものは既にインストール済みだったので、 やったのは下記のライブラリのインストールでした。
brew install watchman
Hello Worldの実行
プロジェクトの作成
下記のコマンドを実行して、プロジェクトの雛形を作成しました。 諸々の必要なパッケージがインストールされます。
$ react-native init iOSTest $ cd iOSTest && npm i $ tree -L 1 . ├── App.js ├── __tests__ ├── android ├── app.json ├── babel.config.js ├── index.js ├── ios ├── metro.config.js ├── node_modules ├── package-lock.json └── package.json
Hello Worldのアプリ作成
Hello World! とだけ表示されるアプリを作成しました。
デフォルトでReactのチュートリアル的な画面が表示されますが、それはコメントアウトして表示されないようにしました。
デフォルトの変更差分には日本語でコメントを書きました。
$ cat index.js
/**
* @format
*/
// View, Textの追加
import {View, Text, AppRegistry} from 'react-native';
// このファイル内にAppを作成するため、App.js(React-Nativeのチュートリアルぽい綺麗なページを表示する)のimportをコメントアウト
// import App from './App';
import React from 'react';
import {name as appName} from './app.json';
// 以下、Hello Worldを表示するviewの作成
const App = () => {
const {textStyle, viewStyle} = styles;
return (
<View style={viewStyle}>
<Text style={textStyle}>Hello World!</Text>
</View>
);
};
const styles = {
viewStyle: {
backgroundColor: '#ebebeb',
justifyContent: 'center',
alignItems: 'center',
height: '100%',
},
textStyle: {
fontSize: 40,
},
};
AppRegistry.registerComponent(appName, () => App);
困ったこと
$ react-native run-ios Command `run-ios` unrecognized. Make sure that you have run `npm install` and that you are inside a react-native project.
run-iosしたら上手くいかなかった。- これも再度、
run-iosで解決した。
- これも再度、
$ react-native run-ios
info Found Xcode workspace "iOSTest.xcworkspace"
error Could not parse the simulator list output. Run CLI with --verbose flag for more details.
SyntaxError: Unexpected token I in JSON at position 0
at JSON.parse (<anonymous>)
at runOnSimulator (/Users/kazu/workspace/iOSTest/node_modules/@react-native-community/cli-platform-ios/build/commands/runIOS/index.js:130:23)
at Object.runIOS [as func] (/Users/kazu/workspace/iOSTest/node_modules/@react-native-community/cli-platform-ios/build/commands/runIOS/index.js:100:12)
at Command.handleAction (/Users/kazu/workspace/iOSTest/node_modules/react-native/node_modules/@react-native-community/cli/build/index.js:164:23)
at Command.listener (/Users/kazu/workspace/iOSTest/node_modules/commander/index.js:315:8)
at Command.emit (events.js:209:13)
at Command.parseArgs (/Users/kazu/workspace/iOSTest/node_modules/commander/index.js:651:12)
at Command.parse (/Users/kazu/workspace/iOSTest/node_modules/commander/index.js:474:21)
at setupAndRun (/Users/kazu/workspace/iOSTest/node_modules/react-native/node_modules/@react-native-community/cli/build/index.js:237:24)
at Object.run (/Users/kazu/workspace/iOSTest/node_modules/react-native/node_modules/@react-native-community/cli/build/index.js:184:11)
- Hello Worldのアプリ作成したらこんな画面になった。
- これ見ながら、build cacheの削除で解決しました。

やってみた感想
Reactに関しては、社内の研修をそれなりに受けたので、ほぼ実務経験はないですが、
なんとなく理解でき、そして過去 NativeのAndroidのアプリを Android-Java で開発したことがあったので
すごく簡単にアプリが作れるなと思いました。
React-Nativeの理解を進めていくことで、今後もっと複雑なアプリが書けるように精進しようと思います。 次は、Backendと連携して、Viewを変更するやつとかやってみようかな、と思います。
FaaSのIacに関して「Zappa」で立ち向かってみる
この記事はRecruit Engineers Advent Calendar 2019 の19日目の記事です。
こんにちは @kazu0716 です
サーバサイド開発、インフラ/ミドルの構築・運用、データ分析/基盤構築・運用、クラウドセキュリティに関して考えることをしています
最近は、オンプレ環境からのPublicクラウドへの移行をもっぱらやってます
今回も、ノリでアドベントカレンダーなんて参加しました
昨年同様ギリギリになって書き出してます。
そして、前回のアドベントカレンダーから、何も書いてないのが今年最大の反省点ですね・・・
ネタはいっぱいあるので、来年こそは!!
Issues of FaaS in our worksplace
lambdaでpythonでなくとも、javascriptやrubyでさくっと何かの処理を自動化したりしたいなーってことよくありますよね
個人で何かやろうってときもそうだし、職場でも無数のlambdaが動いていたりします
lambda や cloud function は FaaS(Function as a Service) に分類されるそうですが
さくっと作ってそのまま放置とかされると、結構厄介かなというのがあり、きちんと管理したいなと思うことがよくありました
最近だと、lamdbaのランタイムのEOL等で、既存の動いているlambdaを見たときに「なんやねんこれ!どこにソースあんねん!」ってなりましたww
- こういうのとか

- こういうのとか

私はPythonが好きで、何やるにもだいたいpythonでやるので、pythonでlambda作るとき/管理するのに便利なツールないかなと探していました
What's Zappa
Zappaとはpythonをlambdaにdeplyする便利ツールです
API-GatewayやCloudWatchも一緒にdeployしてくれたりと便利なのですが、個人的には lambdaのIac(Infrastructure as a code) ができるのが良いなと思ってます
Iac(Infrastructure as a code)の詳細に関しては、リンク先のwikiを読んでいただくのが良いかと思いますが、私がやりたきことは
- lambdaやAPI-Gateway、CludWatchの設定情報をgithubでソースコード管理したい(AWS key等のCredentialな情報は除く)
- 設定変更をし、deployやupdateをコマンド1行とかで手軽にしたい
- s3にソースをuplodaして、AWSコンパネからボタンをぽちぽちしたくない。。。
を満たしてくれる、この便利ツールを早速使ってみようと思います
How to use Zappa
ZappaでFlaskとAPI-Gatewayとかってのは、既に記事があるので今回は、CloudWatchでCron的にPython Scriptを実行してみようと思います
What's you make
監視のSciprtでcronで定期的にクローリングして、その結果をDatadogに飛ばすものを作ろうと思います
FaceBookやGooglePlayが落ちてないか、もしくは担当サービスのStaticページが落ちてないかの監視をするために作りました
Deploy lambda by using Zappa
とっても簡単です。Zappaサイコー!!
- AWS Commandをインストールし、アクセスキー等の認証情報を設定します
$ aws configure AWS Access Key ID [****************4HN5]: AWS Secret Access Key [****************c78Q]: Default region name [ap-northeast-1]: Default output format [None]:
- zappaコマンドでs3経由でlambdaにdeployする(参考)
# 初回時 $ zappa deploy dev # 既に起動している場合はupdateする $ zappa update dev
- cloudwatchのログも確認できる
$ zappa tail dev
Settings Zappa
Deployは簡単なのですが、Zappaではlambdaと何かの組み合わせでを細かい設定含め、1コマンドdeplyすることができます
詳細はREADMEを読んでいただくのが良いと思うのですが、今回はこんな感じの設定をしました
$ cat zappa_settings.json
{
"dev": {
"lambda_description": "外部監視用スクリプト",
"app_function": "app.lambda_handler",
"aws_region": "ap-northeast-1",
"profile_name": "default",
"project_name": "external-monitoring",
"runtime": "python3.7",
"s3_bucket": "$hoge$",
"events": [
{
"function": "app.lambda_handler",
"expression": "rate(5 minutes)"
}
],
"apigateway_enabled": false,
"keep_warm": false,
"log_level": "INFO",
"memory_size": 512,
"timeout_seconds": 300,
"manage_roles": true
}
}
ポイントはeventsの設定で特定関数が5分ごとに実行する設定をしている ということになるかと思います
今回はrole等は設定してないですが、この場合問題なく動くのですが、deplyするプロジェクト名を使って自動的に作成してしまうので
zappaでdeployするたびにroleが量産される ということが起こるので、少し注意が必要かと思います
# Advanced settingsから抜粋 "role_name": "MyLambdaRole", // Name of Zappa execution role. Default <project_name>-<env>-ZappaExecutionRole. To use a different, pre-existing policy, you must also set manage_roles to false. "role_arn": "arn:aws:iam::12345:role/app-ZappaLambdaExecutionRole", // ARN of Zappa execution role. Default to None. To use a different, pre-existing policy, you must also set manage_roles to false. This overrides role_name. Use with temporary credentials via GetFederationToken.
Python Script
特に、面白いところはないと思いますwww
可読性を最大にするため、極力謎記法は使ってないです
Credentialな情報は環境変数に設定しているので、その設定は初回のみAWSのコンパネでぽちぽちしています
アクセス先のURL等の情報は config.ini を作って外出ししています
$ cat app.py
# -*- coding: utf-8 -*-
import json
import logging
import os
from configparser import ConfigParser
from threading import Thread
import requests
from bs4 import BeautifulSoup
from datadog import api, initialize
config = ConfigParser()
config.read(os.path.join(os.path.dirname(__file__), './config.ini'), 'UTF-8')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# NOTE: Datadog SDKの初期設定
options = {'api_key': os.environ['APIKEY'],
'app_key': os.environ['APPKEY']}
initialize(**options)
def create_dd_event(title, text, tags):
if api.Event.create(title=title, text=text, tags=tags, alert_type="error")['status'] != "ok":
raise Exception("Datadogへのイベント送信が失敗しました。")
else:
logger.info("datadogにイベント通知しました。")
def monitor_enmusubi():
"""
サイトの外部監視
"""
try:
for url in config["Enmusubi"]:
code = requests.get(config["Enmusubi"][url]).status_code
if code != 200:
create_dd_event(
"サイト({0}, ステータスコード: {1})".format(url, code),
config["Enmusubi"][url],
["env:external", "service:enm", "target:enmusubi"]
)
except Exception as e:
raise e
def monitor_facebook():
"""
Facebookの障害監視
"""
try:
if requests.get(config['Facebook']['Url']).json()['current']['health'] != 1:
create_dd_event(
"Facebook",
config['Facebook']['DashboardUrl'],
["env:external", "service:enm", "target:facebook"]
)
except Exception as e:
raise e
def monitor_app_store():
"""
AppleStoreの障害検知
"""
# TODO: 動的ページなのでSeleniumが必要になるので後回し
pass
def monitor_datadog():
"""
Datadogサービスの障害検知
"""
try:
html = BeautifulSoup(requests.get(config['Datadog']['Url']).text)
if "error" in ["error" for status in html.find_all("span", class_="component-status") if "Operational" not in status.text]:
create_dd_event(
"Datadog",
config['Datadog']['Url'],
["env:external", "service:enm", "target:datadog"]
)
except Exception as e:
raise e
def lambda_handler(event, context):
"""
CloudWatchに定期実行される関数
Parameters
----------
event: dict, required
API Gateway Lambda Proxy Input Format
# api-gateway-simple-proxy-for-lambda-input-format
Event doc: https://docs.aws.amazon.com/apigateway/latest/developerguide/set-up-lambda-proxy-integrations.html
context: object, required
Lambda Context runtime methods and attributes
Context doc: https://docs.aws.amazon.com/lambda/latest/dg/python-context-object.html
"""
try:
results = []
# NOTE: 監視用関数をマルチスレッドで実行
for task in [monitor_datadog, monitor_facebook, monitor_app_store, monitor_enmusubi]:
t = Thread(target=task)
t.start()
results.append(t)
# NOTE: 全てのスレッドが完了したことを確認
for result in results:
result.join()
except Exception as e:
logging.error("エラーが発生しました。" + str(e.args))
終わりに
lambdaとかcloud functionは便利ですが、雑に作らずこういうツール使って、githubにコード残してくれると離任の際に引き継ぎも楽なので、小さなところもIacしていきましょう!
大量の画像の中から同一画像を探す方法
この記事はRecruit Engineers Advent Calendar 2018 の3日目の記事です。
こんばんは。 @kazu0716 です。ノリでアドベントカレンダーなんて参加しましたが、中々記事がかけずかなり焦りました・・・。クソ記事でも書かないよりマシということでご容赦ください。
今回は、大量の画像の中から、同一画像を見つける必要があり、色々調べたのでシェアしようと思います。
なぜやったか
仕事の中で 「不正ユーザは同一グループに属しており、利用する画像は使い回されている」 という仮説を調査する必要がありました。ただ、画像の数が膨大であり、人の目で見て処理をするのは非常に大変だったため、Scriptで処理できないかなと思ったのがキッカケです。
制約事項
仮説が正しかった場合、最終的にはシステム化することも検討していたので、どうせならそこまで見据えて技術を調査しようと思い、下記の制約の元でも実現できるものを探しました。
- 画像データが外部に流出してはいけない
- 数分内で大量の画像(数万件程度)の中から同一画像を検索できる
どのように実現したか
要素技術調査から、同一画像の調査精度、パフォーマンス調査まで実施しました。
要素技術調査
色々調査してく中で「Perceptual Hash」(以下、単純にhashと表現する)という手法を知りました。手法の詳しい内容に関しては下記に譲るとして、本技術の強みとしては、画像のhash同士を比較し、画像の類似度(実際はhash同士のハミング距離)を調べることができるという点にあると考えます。
tech.unifa-e.com kzkohashi.hatenablog.com
今回は、この手法を用いて大量画像の中から同一画像を検索できるPythonのライブラリである「image-match」の調査検証を行なっていきます。
どんなライブラリか
主に下記の2つの機能を持っています。
画像のhashを計算し、DB(ElasticSearch等)にデータを格納する(indexing)
- 入力: 画像のパス(ファイルパス/URLのどちらか)
- 出力: 特になし
DB内にあるデータを検索し、画像の類似度を表示する(search)
- 入力: 画像のパス(ファイルパス/URL)
- 出力: DB内部に格納されている画像との類似度、画像のパス(ファイルパス/URLのどちらか)
- 特定の類似度以上のもののみ出力することも可能
- 公式ドキュメントには0.40以下であれば同一画像と考えてよいとあり、今回はその値を閾値に設定
公式ドキュメントを参考に、簡単な使い方を紹介していこうと思います。今回python2系を使っているのは、image-matchの依存ライブラリであるscikit-image(0.12.x)がローカルの環境のpython3.7.0ではコンパイルでエラーになりpipでinstallできなかった(2018/11: 現在)ためです。
# pythonのVersion
$ python -V
Python 2.7.15
# 利用しているライブラリ
$ pip freeze
certifi==2018.10.15
chardet==3.0.4
dask==0.20.0
decorator==4.3.0
elasticsearch==6.3.1
idna==2.7
image-match==1.1.2
networkx==2.2
numpy==1.15.3
Pillow==5.3.0
requests==2.20.0
scikit-image==0.12.3
scipy==1.1.0
six==1.11.0
toolz==0.9.0
urllib3==1.24
$ ipython
In [1]: from elasticsearch import Elasticsearch
...: from image_match.elasticsearch_driver import SignatureES
In [2]: es = Elasticsearch()
# indexを指定しないとimagesというindexにデータが保存されます
# distance_cutoffで類似度が一定以上のものを結果から除外する
In [3]: ses = SignatureES(es, index="image_match_test",distance_cutoff=0.40)
In [4]: ses.add_image("./data/img/enm/65188/187284.jpg")
# 同一画像なのでdist=0.0になる
In [5]: ses.search_image("./data/img/enm/65188/187284.jpg")
Out[5]:
[{'dist': 0.0,
'id': u'-vh4b2cBZ9Tpnt1Kqfmo',
'metadata': None,
'path': u'./data/img/enm/65188/187284.jpg',
'score': 63.0}]
同一画像認識精度
次に、画像の類似度(実際は、ハッシュ同士のハミング距離)が0.40以下である場合同じ画像になるかを調べて見ました。 flaskで、画像search結果を表示する簡単なwebアプリを作り、人の目で見て同一でないものが混じってないかを調べて見ました。下記が、表示結果イメージになります。
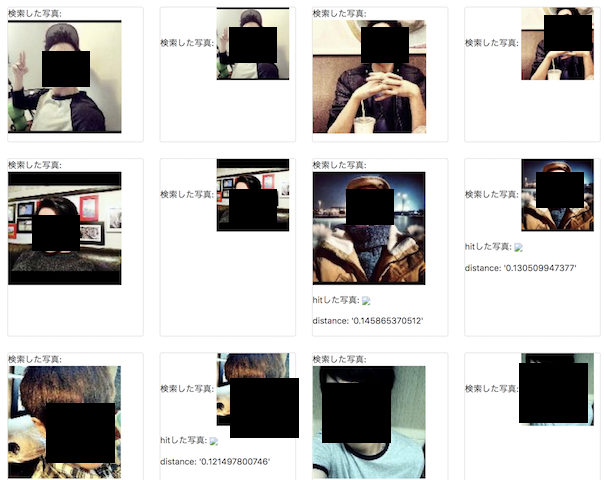
500サンプルくらいを見ましたが、違うものは混じってなさそうでした。ただ、0.40以上で判定され、同じだけど見逃してるものはあったかもしれませんが、今回は誤検知がないことを調べたかったので割愛しました。
パフォーマンスの調査
最後にパフォーマンスの調査を実施しました。利用したマシンのスペックは下記になります。
- OS
- MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)
- CPU
- メモリ
- 16 GB 2133 MHz LPDDR3
調査したのは、処理時間で主に下記の2点になります。
- indexingにかかる時間
| 対象データ数 | かかった時間(sec) |
|---|---|
| 21156 | 862.8 |
CPU負荷: 70%程度でした。時間がかかった理由としては、以下のようなコードで単純にforを回してデータを投入したからであると考えます。ただ、並列処理をしてもElasticSearchへのデータのindexingに限界があるため、そこまでパフォーマンスは上がらないと思われます。
# -*- coding: utf-8 -*-
from __future__ import print_function, unicode_literals, absolute_import
import time
import os
import glob
import threading
import imghdr
from elasticsearch import Elasticsearch
from image_match.elasticsearch_driver import SignatureES
es = Elasticsearch()
ses = SignatureES(es, distance_cutoff=0.40)
def add_images():
img_path = "./data/img/{}/*/*.jpg".format("koi")
image_list = glob.glob(img_path)
for img in image_list:
if imghdr.what(img) is not None:
ses.add_image(str(img))
else:
os.remove(str(img))
def main():
start = time.time()
add_images(service)
print ("elapsed_time:{0}".format(time.time() - start) + "[sec]")
if __name__ == '__main__':
main()
- searchにかかる時間(DB内部の画像データ数: 21156)
| 検索回数 | かかった時間(sec) |
|---|---|
| 10 | 1.38 |
| 100 | 9.72 |
| 1000 | 101.64 |
CPU負荷: 70%程度でした。2万程度の画像を対象に10回検索しても1秒程度で結果が返ってくるので、数分で検索は十分可能であると考えらます。また、検索時間は検索回数に比例しているように思わました。
まとめ
今回大量の画像の中から同一画像を見つけるためにimage-matchというライブラリの調査を実施しました。結果、最低限のコーディングでやりたきことが実現でき、かつローカルでもそれなりにパフォーマンスを発揮することがわかりました。今後は、まずは仮説の立証を行い画像の使い回しを確認し、その後システム化検討の際には、image-matchを検討の1候補にしようと思いました。
最後に
時間を決めて取り組みましたが、あまり内容のある記事を書けなかったので、短時間で人並みの記事が書けるように数を積み重ねることと、outputをイメージしてinputすることで、効率的に成長できると感じたため、inputばかりでなく、こういったブログ等でのoutputの機会を増やしていこうと思いました。